Data profiling involves the use of statistical methods and tools to identify patterns, relationships, and anomalies in data, as well as to assess its consistency, conformity, and compliance with specific standards and requirements. Data profiling is often used in data management and data integration projects to ensure that the data is fit for its intended purpose, and to identify any issues or challenges that may arise during the data processing and analysis stages.
Python
import pandas as pd
# Load data from a CSV file
data = pd.read_csv('my_data.csv')
# Basic statistics about the data
print(data.describe())
# Data types and missing values
print(data.info())
# Unique values in a column
print(data['column_name'].unique())
# Frequency distribution of values in a column
print(data['column_name'].value_counts())
# Correlation matrix between columns
print(data.corr())
R
# Load data from a CSV file
data <- read.csv("my_data.csv")
# Basic statistics about the data
summary(data)
# Data types and missing values
str(data)
# Unique values in a column
unique(data$column_name)
# Frequency distribution of values in a column
table(data$column_name)
# Correlation matrix between columns
cor(data)
Data can have different characteristics that can impact its quality, including accuracy, completeness, timeliness, relevance, and consistency. High-quality data is crucial for decision-making in organizations. To improve data quality, organizations can implement strategies such as establishing data standards, validating data, and providing training.
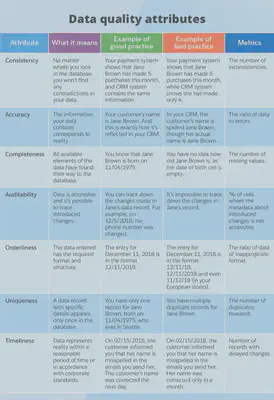
The condition of data plays a crucial role in its capacity to address business objectives. Data quality refers to the degree to which data satisfies specific attributes, and it can either be classified as “good” or “bad”. These attributes include consistency, accuracy, completeness, auditability, orderliness, uniqueness, and timeliness.
The significance of high-quality data cannot be overstated as it has numerous benefits for businesses, including accurate decision making, operational efficiency, customer satisfaction, regulatory compliance, cost reduction, data integration, and interoperability, data analytics and insights, and business intelligence.
Accurate Decision Making
High-quality data guarantees that the conclusions and insights derived from the data are accurate and reliable, ensuring that decisions made are sound. On the other hand, poor data quality can lead to flawed decision-making processes and incorrect conclusions.
Operational Efficiency
Data of high quality also helps organizations achieve operational efficiency by minimizing errors, rework, and delays.
Customer Satisfaction
By streamlining business processes, organizations can execute effectively and provide better customer experiences, which directly impact customer satisfaction.
Regulatory Compliance
Regulatory compliance is another area where high-quality data is essential. Many industries have regulations and compliance requirements related to data quality. Organizations that maintain high-quality data can meet these regulatory obligations and avoid penalties or legal issues.
Cost Reduction
Poor data quality can lead to increased costs, as organizations may waste time and resources rectifying errors, conducting manual data cleansing, or dealing with customer complaints and returns due to incorrect data.
Data Integration and Interoperability
High-quality data is also crucial for data integration and interoperability, as organizations often need to integrate data from multiple sources or share data with external partners. With seamless data integration and improved interoperability between systems, organizations can collaborate better and exchange data more efficiently.
Data Analytics and Insights
Data quality is crucial for accurate and meaningful data analysis, enabling organizations to uncover valuable insights, identify trends, and make data-driven decisions.
Business Intelligence
Organizations rely heavily on business intelligence tools and dashboards to monitor performance, track key metrics, and identify opportunities, and data quality ensures that these tools provide accurate and reliable information for effective business intelligence.
In any organization, encountering data quality issues is almost inevitable. However, ignoring such problems can have long-lasting effects that can leave an indelible mark on the organization. Therefore, it is essential to detect and resolve data quality issues as soon as they arise. To ensure confidence in the data, it must be fit for its intended purpose. Adherence to the CAT-R2 characteristics model is crucial in achieving this goal.
The CAT-R2 model consists of five essential elements that must be considered when evaluating the quality of data. These elements are completeness, accuracy, timeliness, reliability, and relevance.
- Completeness refers to how comprehensive the data is.
- Accuracy pertains to whether the information is correct in every detail.
- Timeliness focuses on how up-to-date the data is and whether it can be used for real-time reporting.
- Reliability assesses whether the information contradicts other trusted resources
- Relevance pertains to whether the information is necessary for the organization’s needs.
Data quality problems are a common occurrence, but they can be avoided and their consequences should be understood. Striving for perfection can cause delays in the delivery process and lead to additional work.
To assess the situation, I usually ask the following questions:
- How will the data be utilized?
- How quickly do our clients require this data?
- How long will it take to correct the data to achieve 100% accuracy?
- What are the ramifications if we don’t address the issue? This aids me in determining if the data is sufficient for my needs, as well as how dependable and precise the output will be, as well as the potential impact. Is the problem significant or can it be postponed until the next iteration?
After that, a decision must be made and communication must be established. The client should be notified so that they can decide whether the current data is sufficient and we can postpone the issue until the next iteration, or if it must be resolved immediately, which may have an impact on their timeline.
References:
Google Developers. (n.d.). Understand the Problem. Retrieved May 5, 2023, from https://developers.google.com/machine-learning/problem-framing/problem
Google Developers. (n.d.). Collect Data for Machine Learning Models: Data Size and Quality. Retrieved May 5, 2023, from https://developers.google.com/machine-learning/data-prep/construct/collect/data-size-quality
Google Developers. (n.d.). Handling Imbalanced Data Sets. Retrieved May 5, 2023, from https://developers.google.com/machine-learning/data-prep/construct/sampling-splitting/imbalanced-data
Google Developers. (n.d.). Data Preparation and Feature Engineering. Retrieved May 5, 2023, from https://developers.google.com/machine-learning/data-prep
Google Developers. (n.d.). Interpret Results and Adjust. Retrieved May 5, 2023, from https://developers.google.com/machine-learning/clustering/interpret
Google Developers. (n.d.). OAuth 2.0 Playground - APIs. Retrieved May 5, 2023, from https://developers.google.com/oauthplayground
Microsoft Power BI Blog. (2021, May 3). Create Power BI reports in Jupyter Notebooks. Retrieved May 5, 2023, from https://powerbi.microsoft.com/en-us/blog/create-power-bi-reports-in-jupyter-notebooks/
Kroenke, D., & Boyle, R. J. (2017). Using MIS. Boston, MA: Pearson Education.